
Prompt Engineering Best Practices for Claude 4 / GPT / Gemini
I've analyzed the official prompt engineering guidelines from OpenAI (GPT-4.1), Anthropic (Claude 3.7/4/Reasoning), and Google (Gemini) to create the first comprehensive comparison matrix. This comprehensive guide compares prompt engineering techniques across different leading models – helping you get better results from any AI model you use.



The revelation: Each company has developed distinctly different best practices for their own models, revealing fundamental architectural differences in how these AIs process instructions.
Official LLM Provider guildelines Comparison between GPT4.1/Claude4/Claude3.7/Gemini2.5
Getting consistent, high-quality responses from AI models isn't just about asking nicely. Whether you're using ChatGPT for business automation, Claude for complex analysis, or Gemini for creative projects, each AI model has its own "language" and optimal prompting strategies.
The problem? Most guides focus on a single model, leaving you to guess how techniques translate across platforms. You might master GPT-4 prompts only to struggle with Claude, or nail Gemini's formatting requirements but hit walls with ChatGPT's agent capabilities.
The solution is here. This guide breaks down exactly how to prompt each major AI model for maximum effectiveness. You'll discover:
✅ Model-specific techniques that work reliably across GPT, Claude, and Gemini
✅ Structural frameworks for organizing complex prompts that get results
✅ Common failure modes and how to avoid them (save hours of troubleshooting)
✅ Advanced strategies like chain-of-thought and prompt chaining
✅ Real examples with XML tags, markdown formatting, and role definitions
Main workflow for designing a prompt should follow this:
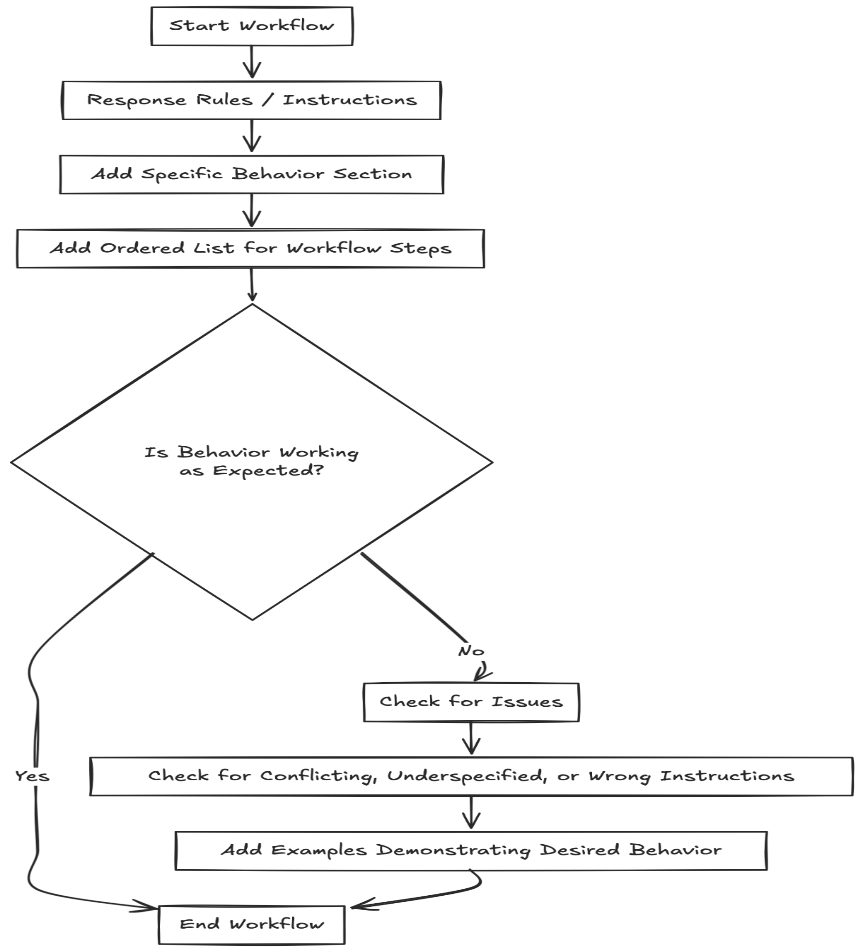
Main Techniques Comparison
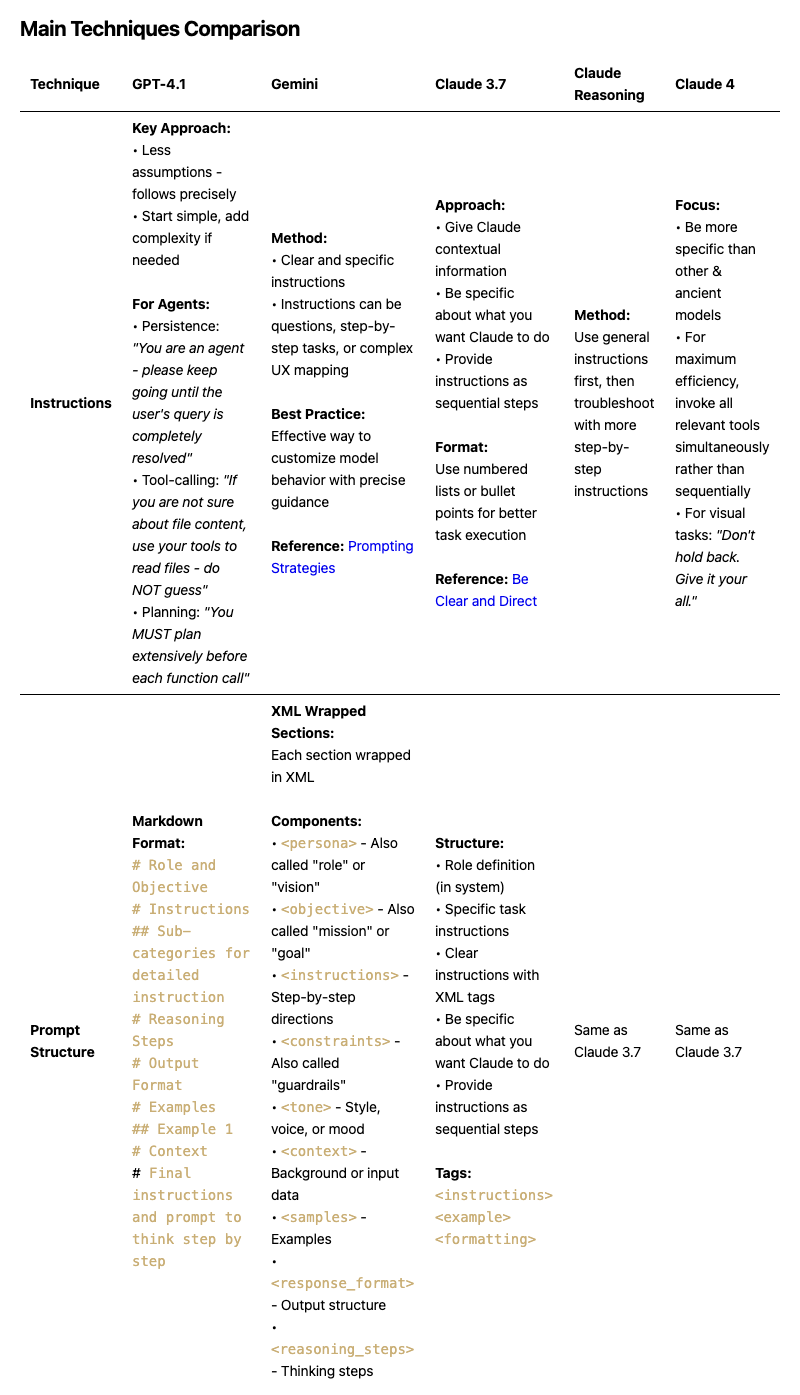
References : [Prompting Strategies] , [Be clear and Direct]
Role Play & Context Handling
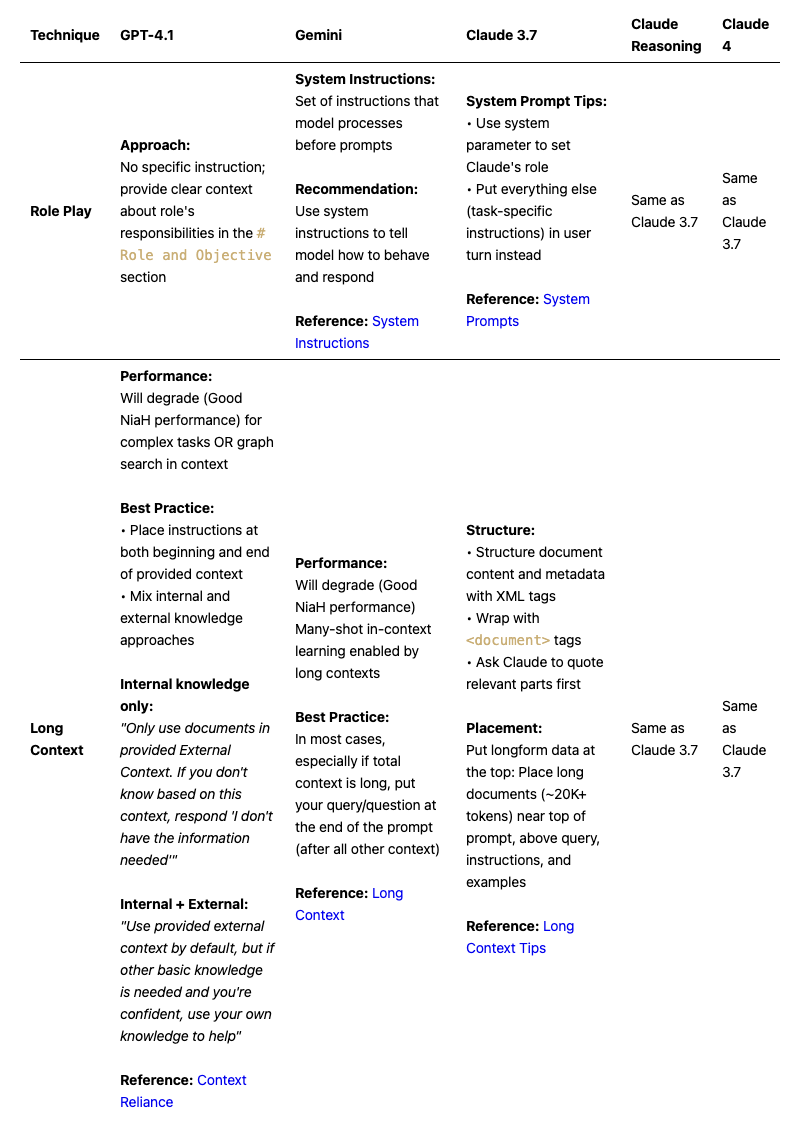
References: [System Instructions], [System Prompts], [Context Reliance], [Long Context], [Long Context Tips]
Formatting & Examples
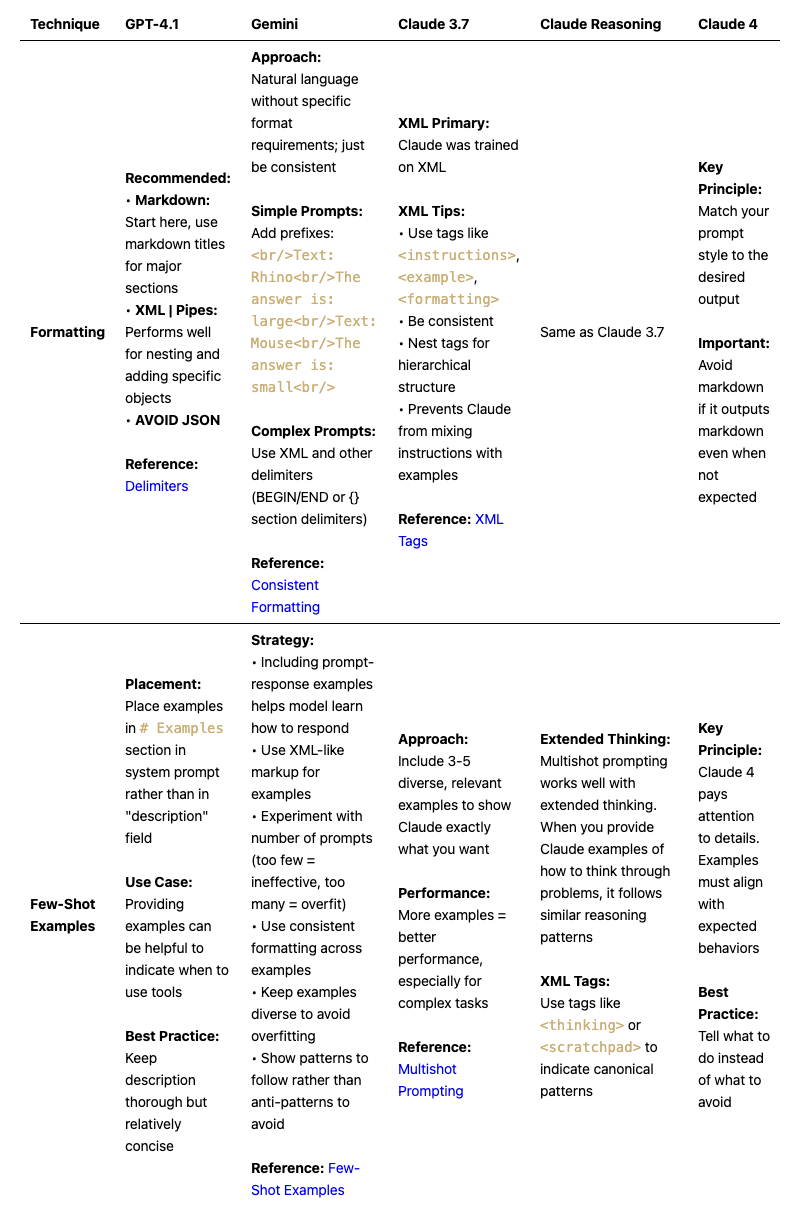
References:
[Delimiters], [Consistent Formatting], [XML Tags], [Few-Shot Examples], [Multishot Prompting]
Advanced Techniques
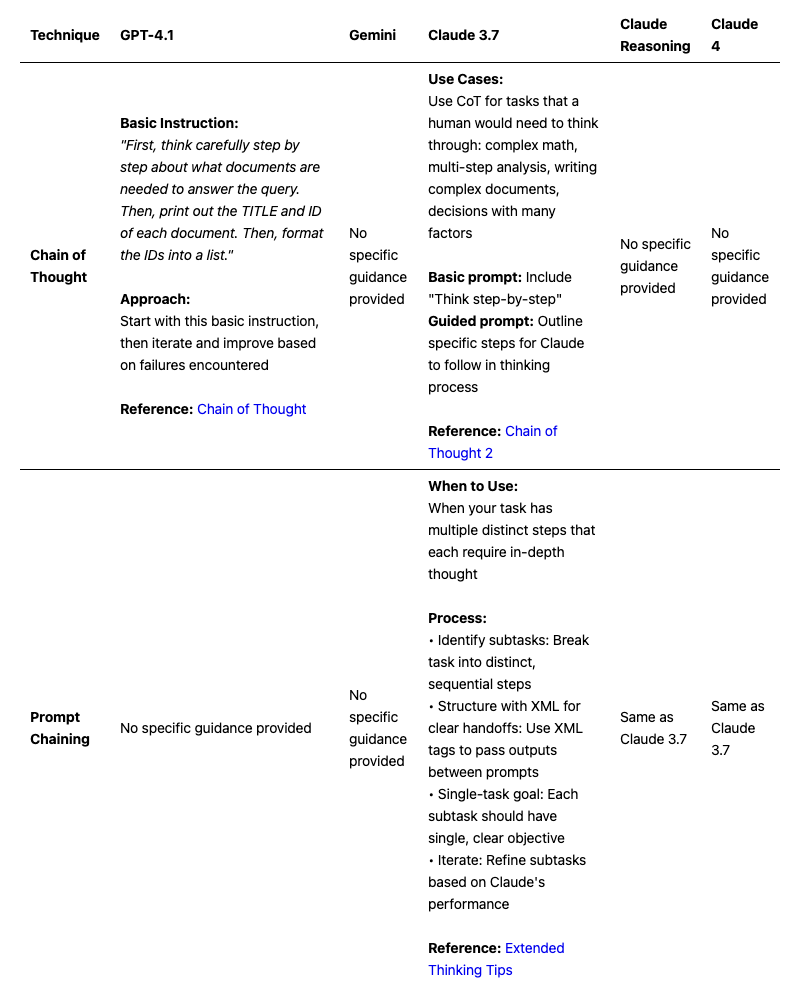
References:
[Chain of Thought], [Chain of Thought 2], [Extended Thinking Tips]
Common Failure Modes
These failure modes are not unique to any specific model, but we share them here for general awareness and ease of debugging.
1. Forced Behaviors
Instructing a model to always follow a specific behavior can occasionally induce adverse effects. For instance, if told *"you must call a tool before responding to the user,"* models may hallucinate tool inputs or call the tool with null values if they do not have enough information.
Mitigation: Add conditional instructions like *"if you don't have enough information to call the tool, ask the user for the information you need"* to provide fallback options.
2. Repetitive Sample Phrases
When provided sample phrases, models can use those quotes verbatim and start to sound repetitive to users. This is especially problematic in customer-facing applications where natural variation is important.
**Mitigation:** Instruct the model to vary phrases as necessary: *"Use these examples as inspiration but vary the language naturally"* or *"Paraphrase these examples rather than using them exactly."*
3. Over-explaining and Excessive Formatting
Without specific instructions, some models can be eager to provide additional prose to explain their decisions, or output more formatting in responses than may be desired. This can make responses verbose and hard to parse.
Mitigation: Provide clear instructions about output format and length: *"Provide only the requested information without additional explanation"* or *"Use minimal formatting - respond with plain text only."* Consider providing examples that demonstrate the desired conciseness.
4. Context and Instruction Mixing
Models can sometimes confuse instructions with data, especially in long contexts where examples, instructions, and actual content are interwoven.
Mitigation: Use clear delimiters (XML tags, markdown sections, or other consistent formatting) to separate different types of content. Structure prompts with distinct sections for role, instructions, examples, and data.
5. Tool Hallucination
When instructed to use tools but lacking sufficient information, models may fabricate tool parameters or make inappropriate tool calls rather than acknowledging limitations.
Mitigation: Always provide clear conditions for tool usage and explicit instructions for handling uncertainty: *"If you're unsure about any parameter, ask for clarification rather than guessing."*
📋 Sourced from: OpenAI Cookbook • Anthropic Documentation • Google AI Documentation • Provider best practice guides
Keywords: official AI guidelines, GPT-4 documentation, Claude prompting guide, Gemini best practices, provider recommendations, AI model optimization, prompt engineering standards
Want receive the best AI & DATA insights? Subscribe now!
• Latest new on data engineering
• How to design Production ready AI Systems
• Curated list of material to Become the ultimate AI Engineer


