
LLM Self-hosted Deployment Roadmap: From Zero to Production
Deploy Vision Language Models at **$187/month** with our breakthrough automation guide. Achieve **4000+ documents/hour processing** with very high precision using advanced quantization (W8A8, FP8 KV cache) on Consumer grade hardware like RTX 4000 Ada. Our one-command deployment system includes automated RunPod integration, real-time monitoring, and production-grade performance benchmarks—transforming complex VLM deployment into a 30-second, cost-effective operation. Real-world testing shows 1.92 requests/sec with 97-99% accuracy retention, making enterprise-grade document processing accessible to teams of any size.



Complete Guide to Production-Ready Qwen2.5-VL Deployment with Full Automation
This guide focuses on production-grade deployment with automated pod creation, monitoring, and scaling for single-node setups using RunPod's infrastructure.
Motivation
First of all, Many thanks to the community, LLM researchers and open-source model providers for their work and contributions to the field of LLM.
My ambition is to leverage a real world use-case to provide a complete guide to production-ready deployment of your favorite LLM models, with a focus on automation and scalability.
I will focus on VLMs as it edges with what i've been working on. But you can "easily" generalize the guide to any LLM.
For sake of simplicity, I will also focus on the deployment on a single node, with a single GPU. Multi-Node deployment is a bit more complex and will be covered in a future guide. If any of you are interested, please let me know or reach out to me on LinkedIn.
Moreover, it's important to understand that each of the following sections are very broad subjects by their own. I will try to make them as self-contained as possible to make this use-case exploration self-sufficient.
Seet this more as a handbook that is by no means exhaustive but very useful to understand the different aspects of the deployment.
Table of Contents
- Production Overview & Requirements
- Memory Calculation Framework
- Understanding Quantization Strategies
- GPU Selection & Theoretical Requirements
- Inference Engine Comparison
- Automated Pod Deployment
- Production Monitoring & Throughput
- Real-World Testing & Validation
Production Overview & Requirements
The main goal of this deployment is to provide a high-volume document processing service. The main requirements are :
- Performance : 2000+ documents/hour sustained
- Precision : 90%+ accuracy
- Reliability : 99% uptime
- Latency : < 20 seconds for document processing - Not expected to be real-time
Production-Grade Deployment Characteristics
For production deployments, we need to first define the requirements. And for that we will navigate between the basic expectations that any system should have and the specific requirements for LLMs.

For a first step, we will focus on a single-pod deployment.
Architecture of self-Deployment Strateegy
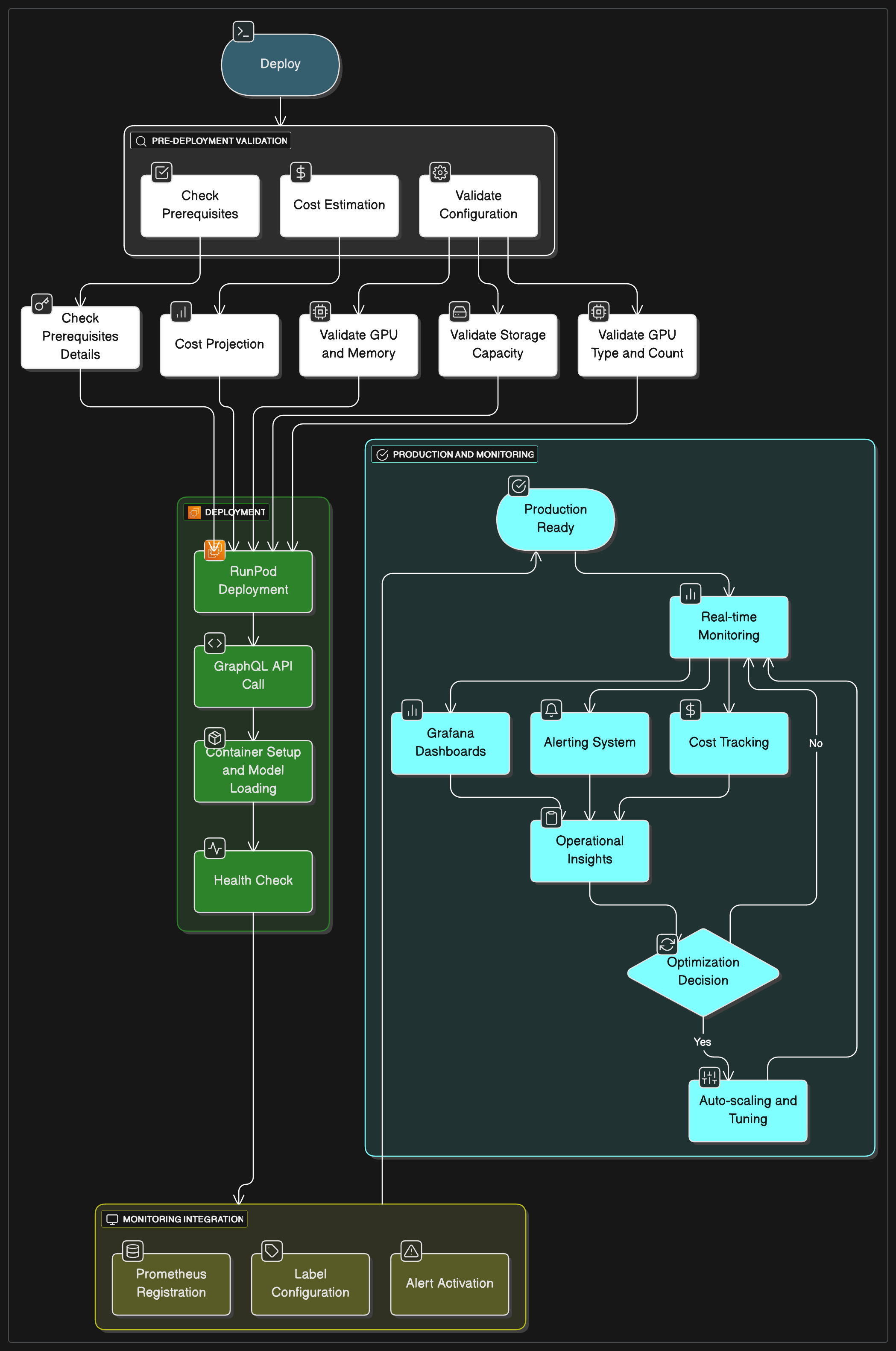
Before diving in any technical choices, we need to understand the basics of LLM deployments. Quantization is a key factor in the deployment of LLMs. By now, i hope size of the model is commonly known by everyone. But let's recap it quickly.
Quick breakdown :
Model Size : when we talk about the size of the model, we are talking about the number of parameters. Those parameters are the weights of the model that we train on a dataset.
Model Precision : the precision of the model weights and activations. Today the main precisions are FP32, FP16, INT8, INT4. meaning that for each of those precisions, each parameter is stored with a different number of bits. FP32 = 32 bits, FP16 = 16 bits, INT8 = 8 bits, INT4 = 4 bits.
Model Memory : That's what helps us understand the memory footprint of the model. Model Memory = Model Size * Model Precision
KV Cache : The KV cache is a cache of the model's key and value vectors. It is used to store the model's key and value vectors for the next token prediction.
Activations : The activations are the output of the model's layers. They are used to generate the output of the model. During training, the activations are used to compute the loss and update the model weights during backpropagation Storage is then required for backprop. During inference, the activations are used to generate the output of the model.
Memory Calculation Framework
Understanding GPU memory requirements is essential for production planning and quantization decisions:
Memory Components Breakdown
1. Model Weights:
Base Memory = Parameters × Precision_Bytes
- FP16: 2 bytes per parameter
- INT8: 1 byte per parameter
- INT4: 0.5 bytes per parameter
2. KV Cache: ( Key-Value Cache in transformer architecture)
KV Cache = 2[for Key + Value] × Layers × KV_Heads × Head_Dim × Sequence_Length × Batch_Size × Precision_Bytes
Key Parameters:
- Query_Heads = Attention_Heads (same thing, different names)
- Head_Dim = Hidden_Size / Query_Heads
- KV_Heads: Number of key-value heads (≤ Query_Heads)
Attention Mechanisms:
- Multi-Head Attention (MHA): KV_Heads = Query_Heads
- Grouped Query Attention (GQA): KV_Heads < Query_Heads (memory efficient)
- Multi-Query Attention (MQA): KV_Heads = 1
Example - Qwen2.5-VL-7B:
- Hidden_Size: 3584, Query_Heads: 28, KV_Heads: 4
- Head_Dim: 3584 / 28 = 128
- KV cache uses 4 heads (not 28), saving 7x memory
3. Activation Memory:
Activations = Batch_Size × Sequence_Length × Hidden_Size × Precision_Bytes
Note: Activations are generally not quantized during inference, they are stored in FP16. Activation memory is not a bottleneck for inference as we do not need to store them for backprop.
4. Framework Overhead:
Overhead = 10-20% of total memory (PyTorch, CUDA kernels, etc.)
Critical Understanding: What Gets Quantized
Model Weights (What Gets Quantized):
- FP16: 2 bytes per parameter
- INT8: 1 byte per parameter
- INT4: 0.5 bytes per parameter
KV Cache & Activations (Usually NOT Quantized):
- Traditional methods (AWQ/GPTQ/GGUF): Weights are quantized, but KV cache and activations remain FP16 (2 bytes per element)
- Advanced methods (W8A8): Both weights AND activations can be quantized to 8-bit
- Reason: Numerical stability and accuracy preservation
Why This Matters:
- Weight quantization saves memory on model storage
- KV cache grows linearly with sequence length and remains unquantized (in traditional methods)
- For long sequences, unquantized KV cache can dominate total memory usage
- This is why quantization benefits diminish with very long contexts
Qwen2.5-VL Memory Requirements
Theoretical Memory Calculations
Qwen2.5-VL-7B Model:
- Parameters: 7.6B (including vision encoder)
- Hidden Size: 3584
- Layers: 28
- Context Length: 32K tokens
Memory Requirements by Precision:
Memory Requirements (32K context, INFERENCE ONLY):
KV Cache details : 2 * 28 * 4 * 128 * 32768 * 2 = 1,87 GB
Key Insights:
- Inference vs Training: No need to store intermediate activations for backprop
- For 32K context: Model weights dominate memory usage (1.87GB KV cache vs 15.2GB FP16 weights)
- INT4 quantization saves ~8.87GB, INT8 saves ~11.87GB from model weights
- KV cache remains 1.87GB regardless of weight quantization (traditional methods)
- W8A8 advantage: Also quantizes activations (0.7GB → 0.35GB)
- Activations minimal: Only 0.7GB for inference vs 1.5GB+ for training
⚠️ Important Reality Check: For long document processing (>8K tokens), the KV cache becomes the bottleneck, not the model weights.
Memory Scaling Example (Qwen2.5-VL-7B AWQ):
- Model weights (INT4): ~3.8GB
- KV cache at 8K tokens: ~0.46GB
- KV cache at 32K tokens: ~1.87GB
- KV cache at 128K tokens: ~7.48GB
This understanding is crucial for choosing the right quantization strategy for your use case.
Understanding Quantization Strategies
Quantization is the process of reducing the precision of model weights to reduce memory footprint and improve inference speed. Important: Most modern quantization methods (AWQ, GPTQ, GGUF) only quantize model weights, while activations and KV cache typically remain in higher precision (FP16) for numerical stability and accuracy. ( As opposed to, rarer W8A8 - a quantization method that quantizes model weights to 8 bits and activations to 8 bits.)
Quantization Impact Analysis
Understanding quantization is crucial for production deployment decisions. Here's a comprehensive breakdown:
1. GGUF (GPT-Generated Unified Format)
What is GGUF:
- Successor to GGML format, optimized for llama.cpp
- Designed for CPU and consumer GPU inference
- Excellent for edge deployment and resource-constrained environments
GGUF Quantization Levels:
GGUF Pros:
- Excellent CPU performance
- Wide hardware compatibility
- Mature ecosystem (llama.cpp)
- Good compression ratios
GGUF Cons:
- Primarily CPU-focused
- Limited GPU acceleration compared to other formats
- Not optimal for high-throughput production
2. AWQ (Activation-aware Weight Quantization)
What is AWQ:
- Quantizes only model weights to INT4 based on activation patterns
- Activations and KV cache remain in FP16 for numerical stability
- Optimized for GPU inference with minimal quality loss
AWQ Characteristics:
- Weight Precision: INT4 (4-bit weights only)
- Activations/KV Cache: FP16 (unquantized)
- Memory Reduction: ~75% for model weights, but KV cache dominates for long sequences
- Quality Retention: 95-98% of original performance
- GPU Optimization: Designed for CUDA acceleration
AWQ Production Benefits:
- Excellent GPU utilization
- High inference speed
- Good quality preservation
- Wide model support
AWQ Limitations:
- Requires CUDA-compatible GPUs
- KV cache remains unquantized (memory bottleneck for long sequences)
- Conversion process can be time-consuming
- Memory scaling: For long contexts, unquantized KV cache can use more memory than quantized weights
3. GPTQ (GPT Quantization)
What is GPTQ:
- Post-training quantization using optimal brain surgeon approach
- Quantizes only model weights, activations and KV cache remain FP16
- Layer-wise quantization with configurable bit widths
GPTQ Characteristics:
- Weight Precision: Configurable (2-8 bits, commonly INT4)
- Activations/KV Cache: FP16 (unquantized)
- Memory Reduction: 50-87% for model weights depending on bit width
- Quality: Good preservation with proper calibration
- Flexibility: Multiple precision options for weights
4. BitsAndBytes (BnB) Quantization
What is BitsAndBytes:
- Dynamic quantization library by Hugging Face
- Supports both INT8 and INT4 quantization with different algorithms
- Designed for easy integration with Transformers library
BitsAndBytes Variants:
- INT8: Linear quantization with outlier detection
- INT4 (NF4): 4-bit NormalFloat quantization optimized for neural networks
- QLoRA: Quantized Low-Rank Adaptation for efficient fine-tuning
BnB Characteristics:
- Weight Precision: INT8 or INT4 (NF4)
- Activations/KV Cache: FP16 (unquantized)
- Memory Reduction: 50-75% depending on precision
- Quality: Good preservation, especially with NF4
- Integration: Native Hugging Face Transformers support
BnB Production Benefits:
- Easy integration with existing HF pipelines
- Good balance of quality and memory savings
- Supports both inference and fine-tuning
- Well-documented and maintained
BnB Limitations:
- Primarily designed for Hugging Face ecosystem
- May have slower inference compared to AWQ/GPTQ
- Less optimized for high-throughput production
5. W8A8 (8-bit Weights and Activations) Quantization
What is W8A8:
- Quantizes both model weights AND activations to 8-bit precision
- Unlike other methods that only quantize weights, W8A8 also quantizes intermediate activations
- Represents the cutting edge of production quantization (2024-2025 breakthrough)
- Requires calibration data and advanced techniques like SmoothQuant for optimal results
W8A8 Variants:
- W8A8-FP: 8-bit floating point for both weights and activations (effectively lossless)
- W8A8-INT: 8-bit integer quantization with proper calibration (1-3% accuracy degradation)
- W8A8 with SmoothQuant: Enhanced activation quantization using smoothing techniques
W8A8 Characteristics:
- Weight Precision: INT8 or FP8 (8-bit weights)
- Activations: INT8 or FP8 (8-bit activations - unique advantage)
- KV Cache: Can be quantized to FP8 for additional memory savings
- Memory Reduction: ~50% for model weights + ~50% for activations = significant total savings
- Compute Throughput: ~2x speedup in inference due to 8-bit operations
- Quality: W8A8-FP is lossless, W8A8-INT achieves 97-99% accuracy retention
- Unique Advantage: Only major method that quantizes both weights AND activations
W8A8 Production Benefits:
- Maximum Memory Efficiency: Quantizes both weights AND activations (unique among major methods)
- High Throughput: up to 1.6x single-stream speedup due to 8-bit arithmetic operations
- Production Ready: Available in vLLM, TensorRT-LLM, and other major inference engines
- Scalability: Particularly effective for high-throughput, asynchronous batching workloads
- Hardware Optimization: Leverages modern GPU 8-bit tensor cores efficiently
W8A8 Limitations:
- Calibration Required: Needs representative calibration dataset for optimal results
- Complexity: More complex setup compared to weight-only quantization methods
- Hardware Dependency: Requires modern GPUs with efficient 8-bit tensor operations
- Latency Trade-off: Better for throughput than ultra-low latency applications
- Model Support: Still expanding across different model architectures
The Broader Quantization Landscape
Beyond the Main Methods: The quantization field is rapidly evolving with many specialized approaches:
- SmoothQuant: Activation-aware quantization for both weights and activations
- LLM.int8(): Outlier-aware INT8 quantization (part of BitsAndBytes)
- SPQR: Sparse-Quantized Representation for very large models
- QuIP: Quantization with Incoherence Processing
- OmniQuant: Omnidirectionally calibrated quantization
- QAT (Quantization-Aware Training): Training models with quantization in mind
- Mixed-Precision: Different precisions for different layers/components
Specialized Techniques:
- Gradient-based methods: BRECQ, AdaRound, QDrop
- Knowledge distillation: Using teacher models to guide quantized student models
- Hardware-specific: Methods optimized for specific accelerators (TPU, NPU)
Quantization Methods Comparison:
Production Quantization
🏆 Tier 1 (Recommended for Production):
- AWQ INT4 + FP8 KV Cache: Maximum memory efficiency for production
- W8A8-FP + FP8 KV Cache: High throughput with excellent quality retention (97-99% accuracy)
- AWQ INT4: Best balance without KV cache quantization
- Use Case: High-throughput document processing, long contexts, asynchronous batching
- Memory Savings: W8A8: 50% total, AWQ: 75% (weights) + 50% (KV cache) = ~60% total
- Quality Retention: W8A8-FP: lossless, AWQ: 95-98%, W8A8-INT: 97-99% ( But requires calibration data),
🥈 Tier 2 (Alternative Options):
- GPTQ INT4 + FP8 KV Cache: Good alternative with KV cache benefits
- BitsAndBytes INT8 + FP8 KV Cache: Excellent for HuggingFace pipelines
- GPTQ INT8: Conservative quantization approach
- Use Case: Moderate throughput, HF ecosystem integration, concurrent batching
🥉 Tier 3 (Specialized Cases):
- BitsAndBytes NF4: Good quality with HF integration
- GGUF Q4_K_M: For CPU-heavy deployments
- GGUF Q8_0: Maximum quality, higher memory usage
- Use Case: Development, testing, quality-critical applications
🚀 New Tier 1+ (Cutting Edge Production):
- AWQ INT4 + FP8 KV Cache: Enables RTX 3080/4070 for 32K contexts with batching
- Memory: 7.7GB total for 32K context (vs 9.8GB without KV quantization)
- Benefit: 2x more concurrent requests OR 2x longer contexts
- Status: Production-ready in vLLM, experimental in others
⚠️ Important Reality Check: For long document processing (>8K tokens), the KV cache becomes the bottleneck, not the model weights. This means:
KV Cache Quantization: The Next Frontier
Why KV Cache Quantization Matters: As we've seen, KV cache starts to have big impact on memory usage for long contexts. KV cache quantization addresses this directly by reducing the precision of cached key-value pairs.
FP8 KV Cache Implementation
Current State (2024-2025):
- FP8 KV Cache: Available in vLLM and other inference engines
- Memory Benefits: ~2x more space for KV cache allocation
- Quality: Minimal degradation with proper calibration
Performance Impact:
- Throughput: Approximately double the KV cache capacity
- Enables: Either longer context lengths OR more concurrent batches
- Latency: Currently no improvements (no fused dequantization yet)
- Future: Fused operations will improve latency
Production Benefits:
✅ 2x more concurrent requests at same memory
✅ 2x longer context lengths at same memory
✅ Better GPU memory utilization
✅ Reduced memory bottlenecks
⚠️ No latency improvements yet
⚠️ Still experimental in some engines
Memory Impact with KV Cache Quantization
Qwen2.5-VL-7B with FP8 KV Cache (32K context, INFERENCE ONLY):
Key Insights:
- FP8 KV cache halves memory usage for the cache component (1,87GB → 0.935GB)
- Total memory savings: 21% when combining AWQ + FP8 KV cache (10.0GB → 6.385GB)
- W8A8 advantage: Quantizes activations too (0.7GB → 0.35GB), providing additional memory efficiency
- W8A8 trade-off: Higher model weight memory (7.6GB vs 3.8GB) but 2x compute throughput
- Optimal choice: AWQ for memory-constrained scenarios, W8A8 for throughput-critical production
- Enables: Even RTX 3080 (10GB) can handle 32K context with room for batching
- Inference-only: Only 0.35-0.7GB activations (no backprop storage needed)
📊 Mathematical Verification of Memory Calculations
Step-by-Step Breakdown for Qwen2.5-VL-7B (32K context):
1. Model Weights Calculation:
Base Parameters: ~7B
AWQ INT4: 7B × 0.5 bytes = 3.5GB + 0.3GB (vision encoder) = 3.8GB ✓
INT8 methods: 7B × 1 byte = 7.0GB + 0.6GB (vision encoder) = 7.6GB ✓
2. KV Cache Calculation:
Estimated Architecture: 28 layers, 4 KV heads, (3584/28) = 128 head dimension
Formula: 2 × Layers × KV_Heads × Head_Dim × Sequence_Length × Precision
FP8 KV Cache:
2 × 28 × 4 × 128 × 32,768 × 1 byte[FP8 Precision] = 939,524,096 bytes = 0.939GB ≈ 0.935GB ✓
FP16 KV Cache:
0.935GB × 2 = 1.87GB ≈ 1.87GB ✓
3. Activations Calculation:
Standard (FP16): 0.7GB (includes vision processing overhead)
W8A8 (INT8): 0.7GB ÷ 2 = 0.35GB ✓ (activations quantized to 8-bit)
4. Framework Overhead:
Standard configurations: 1.5GB (CUDA context, buffers, model loading)
Quantized configurations: 1.3GB (reduced due to memory efficiency)
Memory Requirements for QWEN 2.5 VL Model Sizes
Architectural Parameters Used:
- 3B Model: ~36 layers, 2 KV heads, 128 head dimension
- 7B Model: ~28 layers, 4 KV heads, 128 head dimension
- 32B Model: 64 layers, 8 KV heads, 128 head dimension
Qwen2.5-VL-3B with FP8 KV Cache (32K context, INFERENCE ONLY):
KV cache = 2 * 36 * 2 * 128 * 32768 * 1 byte[FP8 Precision] = 603,979,776 bytes = 0.603GB ≈ 0.6GB ✓
Qwen2.5-VL-32B with FP8 KV Cache (32K context, INFERENCE ONLY):
KV cache = 2 * 64 * 8 * 128 * 32768 * 1 byte[FP8 Precision] = 4,294,919,104 bytes ≈ 4.25GB ✓
GPU Selection & Theoretical Requirements
Now that we understand the memory calculation framework and quantization strategies, let's apply this knowledge to select the optimal GPU configuration for production deployment.
GPU Selection Matrix
Production-Ready GPU Options
💰 Major Price Changes (May 2025):
- RTX 4000 Ada: $0.26/hr (NEW - excellent budget option)
- RTX 4090: $0.69/hr (unchanged)
- RTX 6000 Ada: $0.77/hr (down from $1.20 - 36% reduction!)
- H100 variants: $2.39-$6.39/hr (premium tier)
- L40/L40S: $0.43-$0.86/hr (good mid-range options)
🎯 Production Sweet Spots (May 2025):
Ultra-Budget Champion:
- Qwen2.5-VL-3B with AWQ + FP8 KV Cache on RTX 4000 Ada
- Context: Up to 32K tokens
- Cost: $0.26/hr
- Memory: 3.6GB required, 20GB available
- Use Case: Ultra-cost-sensitive production, development, testing
Production Budget Champion:
- Qwen2.5-VL-7B with AWQ + FP8 KV Cache on RTX 4000 Ada
- Context: Up to 32K tokens
- Cost: $0.26/hr
- Memory: 6.4GB required, 20GB available
- Use Case: Cost-sensitive production deployments with excellent performance
Performance Leader:
- Qwen2.5-VL-7B with AWQ + FP8 KV Cache on RTX 4000 Ada
- Context: Up to 32K tokens with maximum throughput
- Cost: $0.26/hr
- Memory: 10.2GB required, 20GB available
- Use Case: High-throughput production (1.6x speedup) at budget pricing
32B Model Champion:
- Qwen2.5-VL-32B with AWQ + FP8 KV Cache on RTX 6000 Ada
- Context: Up to 8K tokens
- Cost: $0.77/hr
- Memory: 20.3GB required, 48GB available
- Use Case: Large model deployment with excellent memory efficiency
Inference Engine Comparison
Production Inference Engine Analysis
Choosing the right inference engine is critical for production performance:
1. vLLM (Recommended for Production)
What is vLLM:
- High-performance inference engine for large language models
- Optimized for throughput and memory efficiency
- Built-in support for continuous batching and paged attention
vLLM Advantages:
- PagedAttention: Efficient KV cache management
- Continuous Batching: Process requests as they arrive
- High Throughput: 2-24x faster than naive implementations
- Memory Efficiency: Optimal GPU memory utilization
- Production Features: Built-in API server, metrics, health checks
vLLM Performance Characteristics:
- Latency: Optimized for throughput over latency
- Concurrency: Excellent multi-request handling
- Memory: Efficient KV cache management
- Scalability: Handles varying request loads well
vLLM Production Benefits:
✅ Built-in OpenAI-compatible API
✅ Automatic request batching
✅ Memory optimization
✅ Production monitoring
✅ Easy deployment
✅ Active development and support
2. NVIDIA TensorRT-LLM
What is TensorRT-LLM:
- NVIDIA's optimized inference engine
- Hardware-specific optimizations for NVIDIA GPUs
- Focus on maximum performance for NVIDIA hardware
TensorRT-LLM Characteristics:
- Performance: Highest performance on NVIDIA GPUs
- Optimization: Hardware-specific kernel optimizations
- Latency: Excellent for low-latency applications
- Complexity: More complex setup and deployment
TensorRT-LLM vs vLLM:
3. llama.cpp
What is llama.cpp:
- CPU-optimized inference engine
- Excellent for edge deployment
- GGUF format native support
llama.cpp Characteristics:
- CPU Performance: Excellent CPU utilization
- Memory Efficiency: Low memory footprint
- Hardware Support: Runs on any hardware
- GPU Support: Limited compared to vLLM
Production Considerations:
- Best for: Edge deployment, CPU-heavy environments
- Not ideal for: High-throughput production servers
- Use case: Development, testing, resource-constrained environments
Production Recommendation: vLLM
Why vLLM for Production:
- Ease of Deployment: Simple Docker container setup
- Production Features: Built-in monitoring, health checks, metrics
- Performance: Excellent throughput for document processing
- Compatibility: OpenAI-compatible API
- Community: Active development and support
- Reliability: Proven in production environments
vLLM Production Architecture:
Internet → Load Balancer → vLLM API Server → GPU → Response
↓
Monitoring & Logging
RUNPOD DEPLOYMENT
Before automating the deployment, Let's just manually deploy a few models to get a feel for the process.
1. Create a new RunPod account/project
2. Choose POD specs
RTX 4090 - this seems to be the best option for the moment given models i want to deploy and benchmark.
but i want to try something stronger. Let's try RTX 6000 ADA. ( & maybe RTX 5090 later)
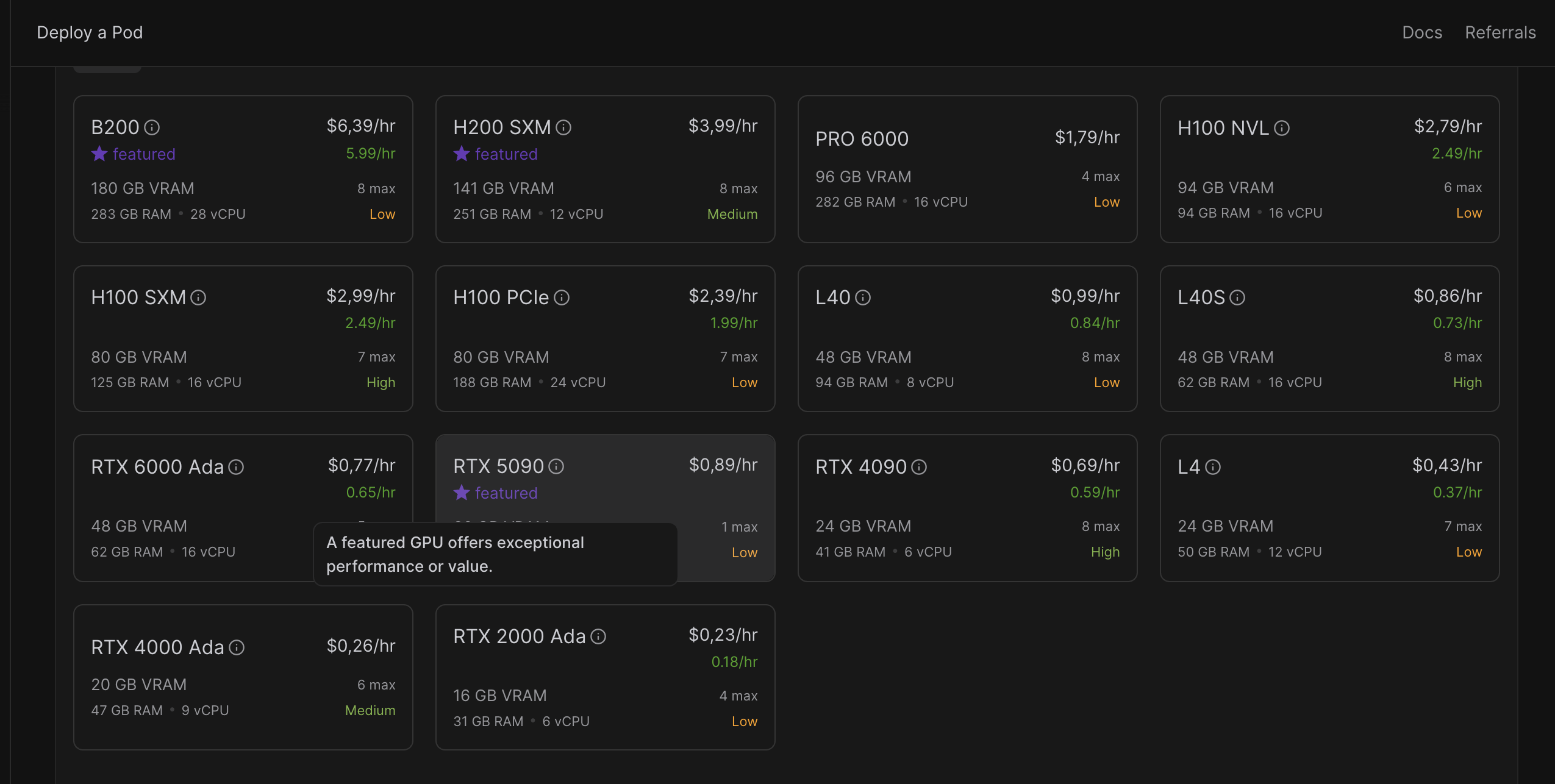
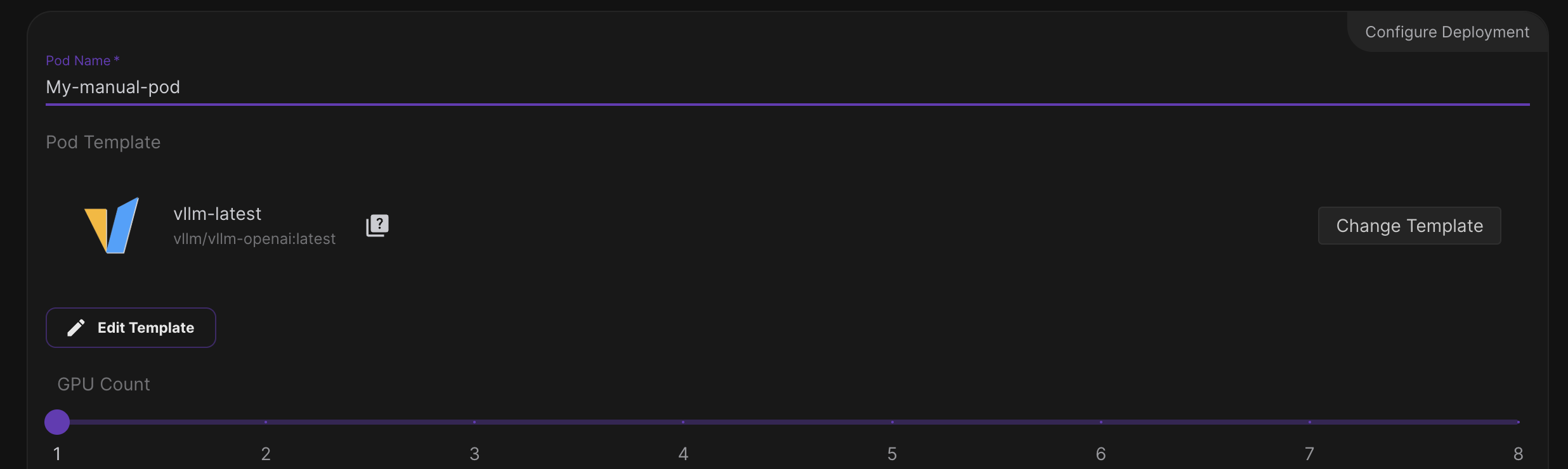
Step 2 : Image Template
We can either choose some base image with ubuntu (e.g. 22.04) but fore sake of simplicity, we will go with apreconfigured vLLM image that serves openAI API.
That will help us iterate quicker.
But basically what it saves us to do is installing & configuring ourselves :
- Cuda, Pytorch, vLLM, launching vLLM
vllm.entrypoints.openai.api_server
Step 2 : Model & Run configs
Once template vLLM is chosen, it allows us to quickly iterate and change models
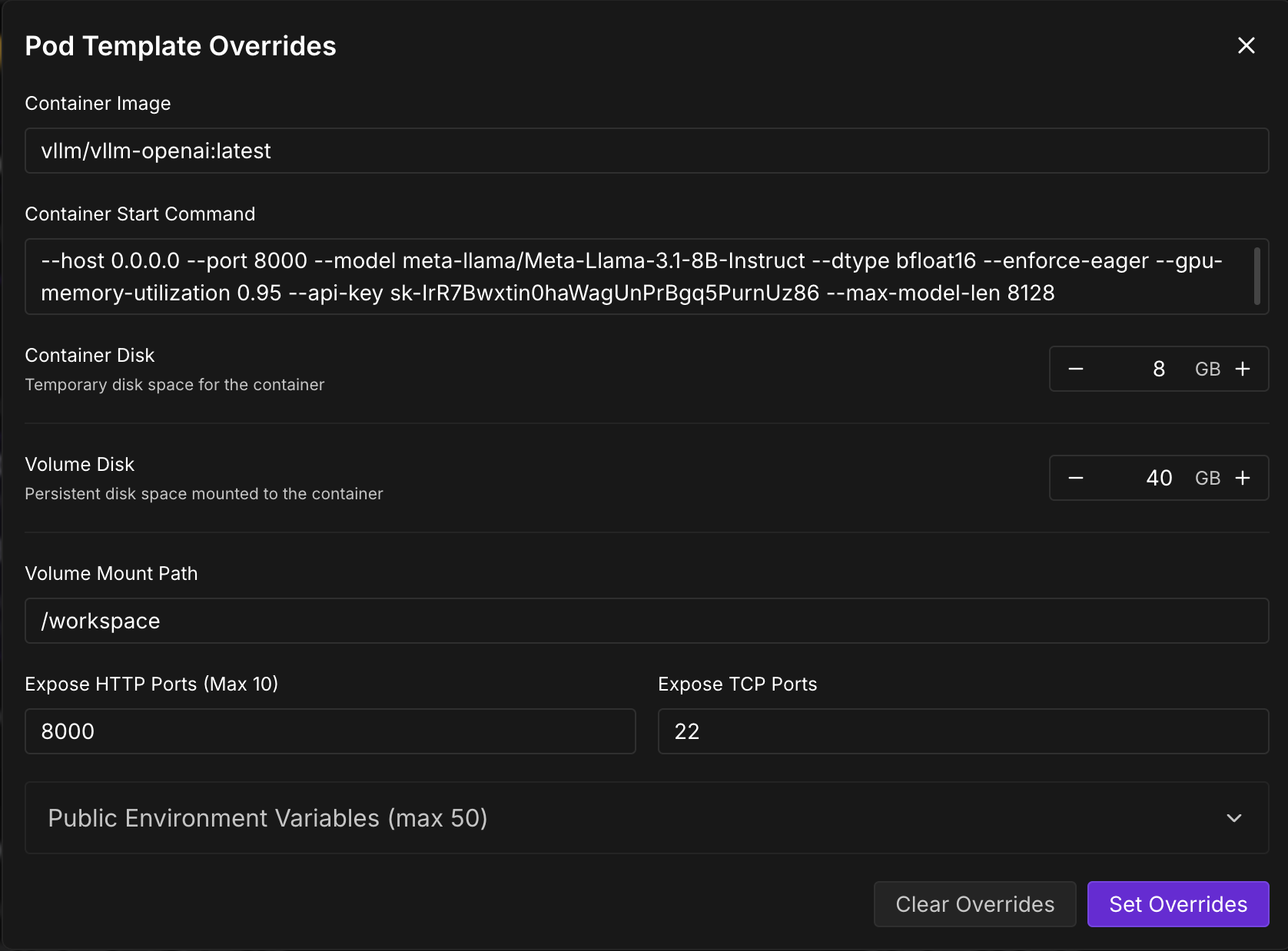
the VLLM Parameters we will be mainly playing with:
--model $Model
--enforce-eager # Eager mode for faster inference
--gpu-memory-utilization 0.95
--api-key test-key-1234
--max-model-len 8128
--dtype float16
--kv-cache-dtype fp8 # Quantize the KV cache to FP8
--calculate-kv-scales # Calculate the KV cache scale
here are some models that i would like to benchmark :
Qwen/Qwen2.5-VL-3B-Instruct-AWQ
Qwen/Qwen2.5-VL-3B-Instruct
RedHatAI/Qwen2.5-VL-7B-Instruct-quantized.w8a8
Qwen/Qwen2.5-VL-7B-Instruct-AWQ
Qwen/Qwen2.5-VL-7B-Instruct
Qwen/Qwen2.5-VL-32B-Instruct-AWQ
reducto/RolmOCR
reducto/RolmOCR:Q4_K_M
Note : Cannot use FlashAttention backend for FP8 KV cache. FlashInfer backend with FP8 KV Cache for better performance by setting environment variable VLLM_ATTENTION_BACKEND=FLASHINFER
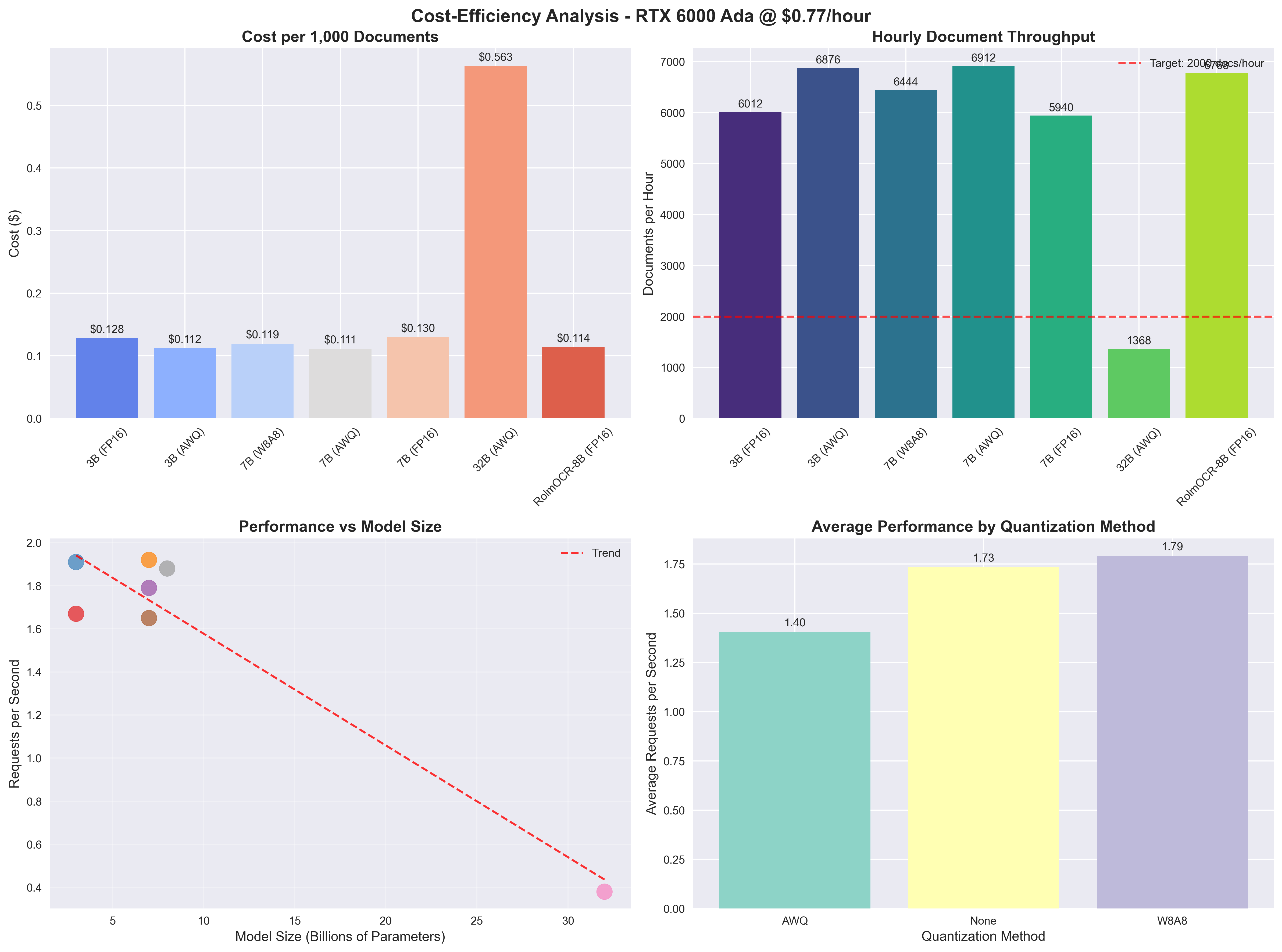
3. Real-World Benchmark Results: RTX 6000 Ada Performance Analysis
Testing Environment:
- GPU: RTX 6000 Ada (48GB VRAM)
- Context Length: 8,128 tokens
- GPU Memory Utilization: 95%
- vLLM Version: Latest with FP8 KV cache support
📊 Performance Summary
📈 Detailed Latency Statistics
Latency Diagrams :
Precision Diagrams :
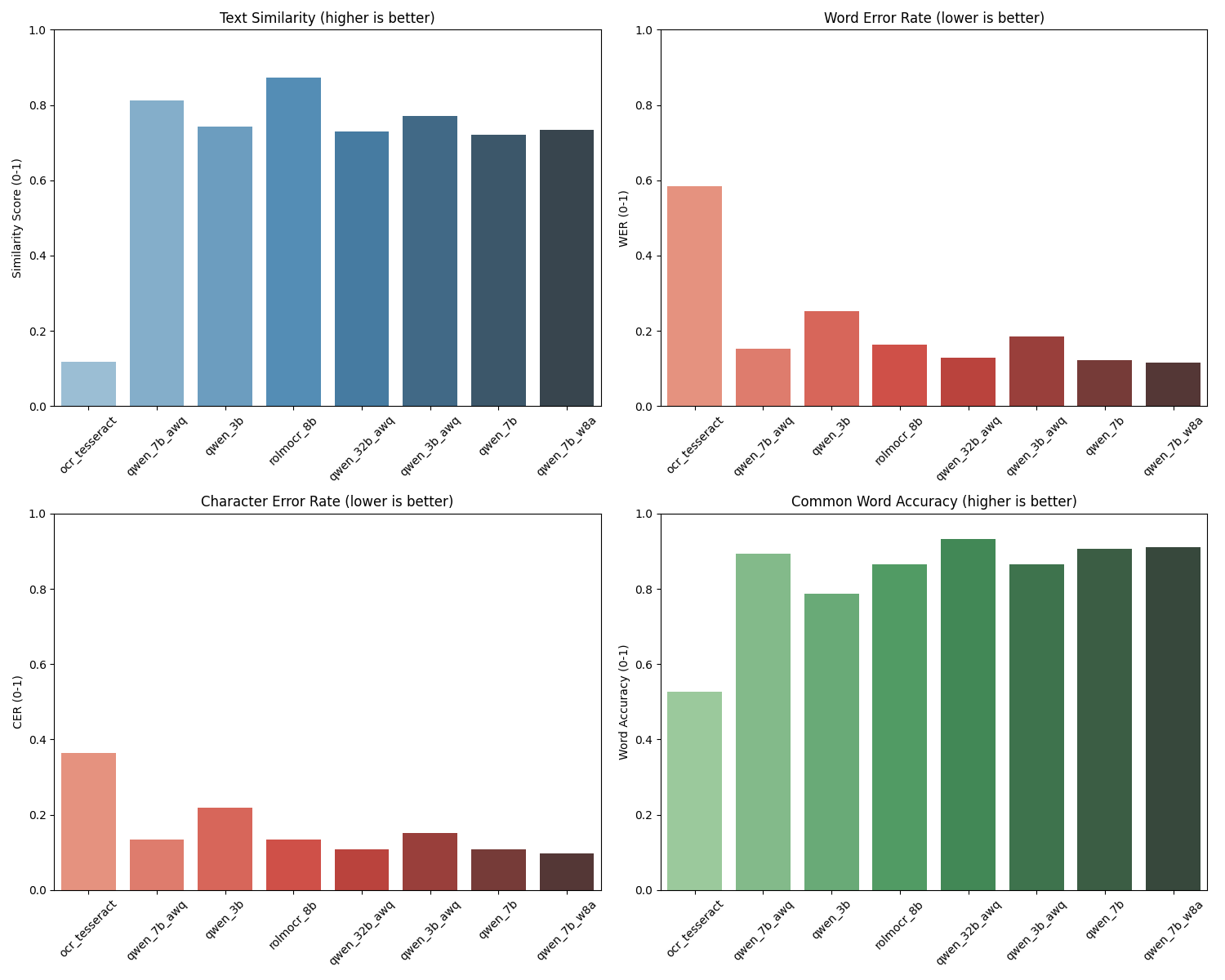
Pleasant surprise, Rolmo Seams to be a good spot with great performances.
This use case becomes really massive so we will continue on a second step on how to automate & monitor all this to get those results.
Sources :
- QWEN 2 Technical Report https://arxiv.org/html/2407.10671v1
- kv-caching https://huggingface.co/blog/not-lain/kv-caching
- Inference Optimization : https://developer.nvidia.com/blog/mastering-llm-techniques-inference-optimization/
Want receive the best maketing insights? Subscribe now!
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Massa adipiscing in at orci semper. Urna, urna.